Member: Jun Rekimoto
Multimodal Large Language Models (MLLMs) are capable of understanding human activities through images, audio, and video, and are applicable to a wide range of human-computer interaction scenarios, including activity support, real-world agents, and skill transfer to robots or other individuals. However, processing high-resolution and long-duration videos consumes substantial computational resources.
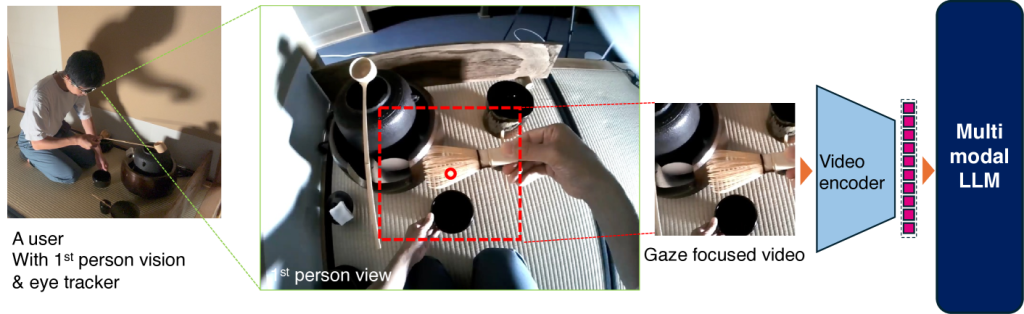
In this study, we propose a method that segments first-person perspective videos based on eye-tracking data and selectively processes image regions where gaze is concentrated. This approach reduces the number of pixels to approximately one-tenth while maintaining or even improving the model’s comprehension performance.
Published Paper : [Download from here]