メンバー: 暦本 純一
マルチモーダル大規模言語モデル(MLLM)は、画像や音声、動画を通じて人間の活動を理解し、人間
の活動支援、実世界エージェント、ロボットや他者への技能移転など多くのヒューマンコンピュータイ
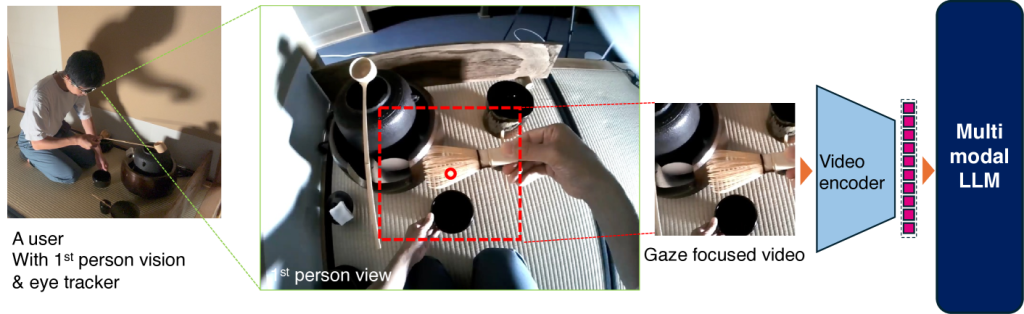
ンタラクションに応用可能です。しかし、高解像度・長時間の動画処理は計算資源を大量に消費します。本研究では、一人称視点映像を視線情報に基づいて分割し、視線が集中する画像領域を選択的に処理することで、画素数を約1/10に削減しつつ、同等以上の理解性能を実現する手法を提案しています。
論文:ダウンロードはこちら